
画像生成AIであるStable DiffusionをWindows11のWSL2 (Ubuntu)にインストールし、アジア人に特化した実写系モデルのBRAV6を利用することで、美人女性のAIグラビア画像を生成しました。期待通りの画像生成ができたので、備忘録としてまとめて置きます。
インストール環境
インストール環境は以下の通りです。グラフィックボードはかなり古いですが、画像の解像度が512×768であれば、20~21秒で生成できました。
- Windows 11
- Ubuntu 22.04.2 LTS
- NVIDIA GeForce GTX 1080 (8GB)
グラボはコストパフォーマンスが良いとされるGeForce RTX 3060 (12GB)を勧めている方が多いようです。以下のサイトでグラボの性能が詳しく比較されています。
【Stable Diffusion】AIイラストにおすすめなグラボをガチで検証
Windows11 WLS2へのStable Diffusionのインストール
WSL2からGPUが認識されていることを確認します。
$ nvidia-smi
Mon May 9 18:26:49 2023
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 530.41.03 Driver Version: 531.41 CUDA Version: 12.1 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA GeForce GTX 1080 On | 00000000:01:00.0 On | N/A |
| 35% 37C P8 10W / 180W| 1400MiB / 8192MiB | 2% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| 0 N/A N/A 143 G /Xwayland N/A |
+---------------------------------------------------------------------------------------+Stable Diffusionのインストールにつきましては、以下のサイトを参考にさせて頂きました。
WSL2でvladmandic/automaticを構築する
まず、必要なパッケージをインストールします。
$ sudo apt install build-essential libffi-dev libssl-dev zlib1g-dev liblzma-dev libbz2-dev libreadline-dev libsqlite3-dev libopencv-dev tk-devPythonのバージョンを指定したいので、pyenvを導入します。
$ git clone https://github.com/pyenv/pyenv.git ~/.pyenvPathの設定を.bashrcに記載後、有効にします。
$ echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bashrc
$ echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bashrc
$ echo 'eval "$(pyenv init --path)"' >> ~/.bashrc
$ echo 'export LD_LIBRARY_PATH=/usr/lib/wsl/lib:$LD_LIBRARY_PATH' >> ~/.bashrc
$ source ~/.bashrc上記のLD_LIBRARY_PATHの設定をしないと、実行時エラーになってしまうようです。
Could not load library libcudnn_cnn_infer.so.8. Error: libcuda.so: cannot open shared object file: No such file or directoryPythonのバージョンを指定してインストールします。
$ pyenv install 3.10.11
$ pyenv global 3.10.11
$ python --version
Python 3.10.11nVidia CUDA toolkitをインストールします。
$ wget https://developer.download.nvidia.com/compute/cuda/repos/wsl-ubuntu/x86_64/cuda-keyring_1.0-1_all.deb
$ sudo dpkg -i cuda-keyring_1.0-1_all.deb
$ sudo apt-get update
$ sudo apt-get -y install cudaStable Diffusion web UIをGitHubからクローンします。
$ git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git stable-diffusion-automatic
$ cd stable-diffusion-automatic
Stable Diffusion web UIを起動します。初回起動時はセットアップも行われます。
$ bash webui.sh
################################################################
Install script for stable-diffusion + Web UI
Tested on Debian 11 (Bullseye)
################################################################
::::
LatentDiffusion: Running in eps-prediction mode
DiffusionWrapper has 859.52 M params.
Applying cross attention optimization (Doggettx).
Textual inversion embeddings loaded(0):
Model loaded in 3.3s (load weights from disk: 0.2s, create model: 0.3s, apply weights to model: 0.7s, apply half(): 0.4s, load VAE: 1.0s, move model to device: 0.6s).
Running on local URL: http://127.0.0.1:7860
To create a public link, set `share=True` in `launch()`.
Startup time: 7.2s (import torch: 0.9s, import gradio: 1.0s, import ldm: 0.5s, other imports: 0.6s, setup codeformer: 0.1s, load scripts: 0.3s, load SD checkpoint: 3.4s, create ui: 0.2s, gradio launch: 0.1s).「Running on local URL:」にあるローカルアドレス(上記ではhttp://127.0.0.1:7860)をブラウザで開くと、Stable Diffusion web UIが起動しました。
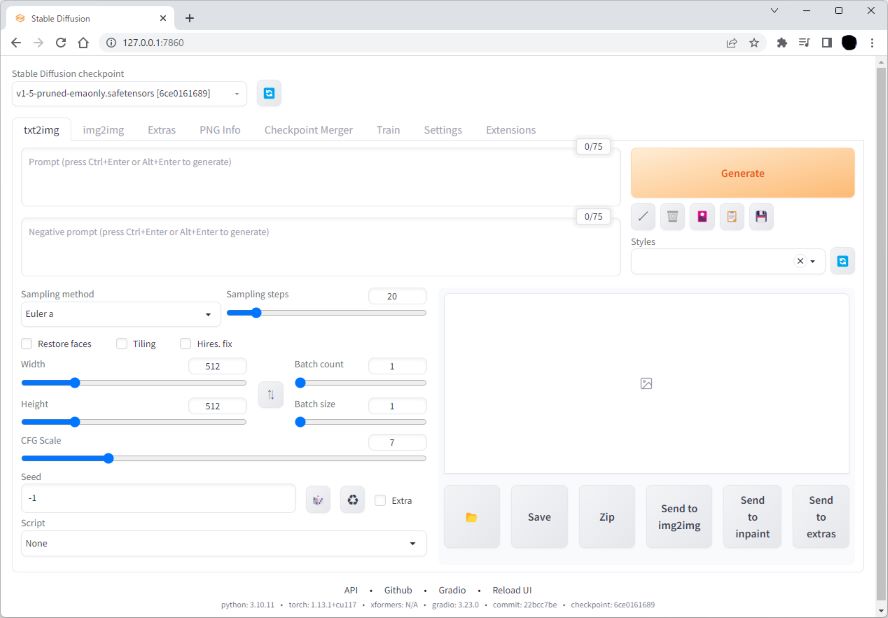
Stable Diffusionで画像生成を行うには、目的に応じたモデルのインストールが必要になります。デフォルトで「v1-5-pruned-emaonly.safetensors」とうモデルが設定されているので、直ぐに利用することができます。まずは試しに、txt2imgのPromptとNegative promptに下記を設定して、Generateボタンで画像生成してみました。
- 【Prompt】 cherry blossoms, riverside
- 【Negative prompt】 low quality
- 他のパラメータはデフォルト設定
待つこと約12秒で、きれいな桜の画像が生成されました。

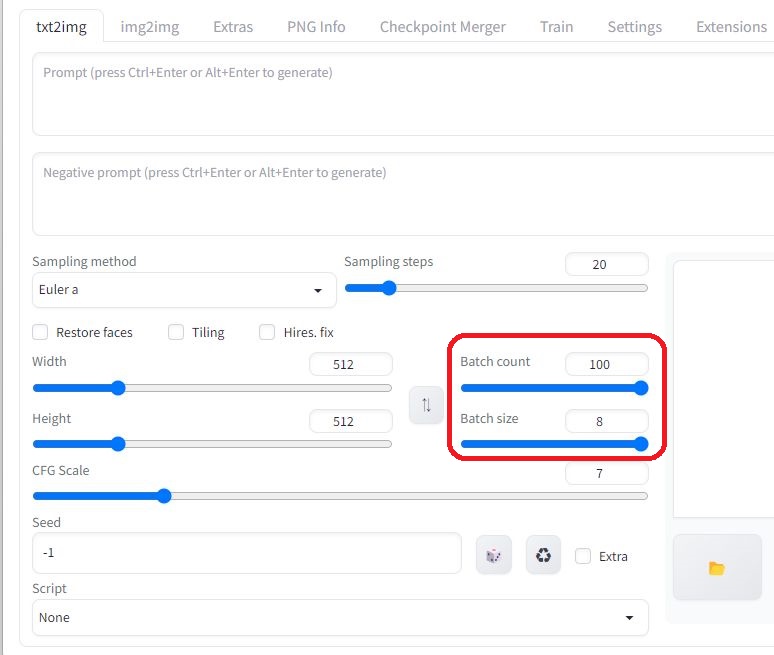
生成する画像数は、「Batch count」×「Batch size」で指定できます。Batch countで生成処理の繰り返し数を、Batch sizeで1回の生成処理における画像数(スレッド並列処理数)を指定します。下図の場合、800枚の異なる画像が生成されます(「Seed」(乱数の種)の「-1」(ランダム)は変更する必要はありません)。Batch sizeを増やすことで並列処理による高速化が期待できますが、GPUのメモリが不足すると、返って処理が遅くなったり、メモリ不足で計算が実行できなくなります。
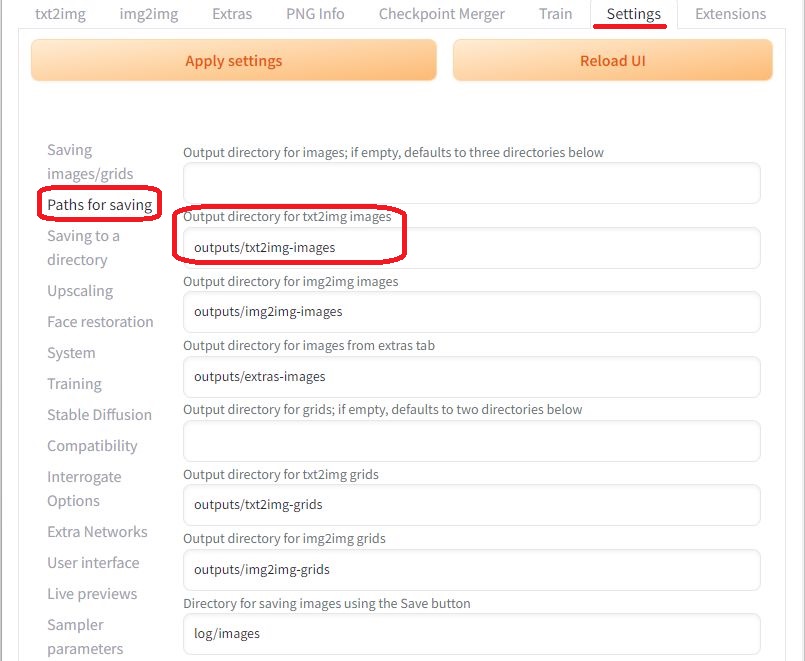
生成した画像の保存先は、「Settings」画面の「Paths for saving」で指定できます。特に変更の必要はありません。
BRA(Beautiful Realistic Asians) V6 (BRAV6)のインストール
BRA V6はアジア人に特化した実写系モデルなので、日本人風のAIグラビアの画像生成にぴったりです。更新が止まっているChilloutMixの代替として注目されているようです。
インストールの方法は、BRAV6モデルファイルを所定のディレクトリにダウンロードするだけです。
# webui.shのあるディレクトリに移動
$ cd stable-diffusion-automatic
# BRAV6モデルのダウンロード
$ wget https://civitai.com/api/download/models/113479 -O ./models/Stable-diffusion/beautifulRealistic_v60.safetensorsモデルのダウンロード後に青いリロードマークをクリックすれば、Stable Diffusion checkpointで「beautifulRealistic_v60.safetensors」が選択可能になります。
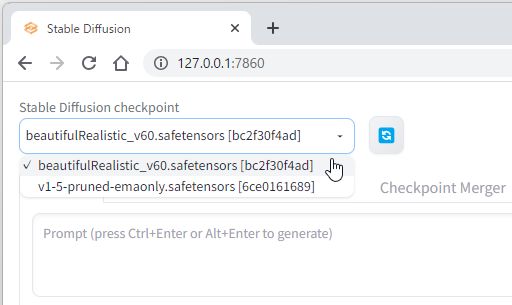
日本人風AIグラビア画像生成
Stable Diffusionで画像生成を行う上で重要な、PromptとNegative promptの与え方については、BraV Quality TagsにあるBRAの作者の記述を参考にさせて頂きました。
【Prompt】
(Best quality, 8k, 32k, Masterpiece, UHD:1.2), Photo of Pretty Japanese woman【Negative prompt】
(Worst Quality:2.0)その他の計算条件として、Stable Diffusionに以下のパラメータを設定しました。
- 【Steps】 20
- 【Sampler】 DPM++ 2M Karras
- 【CFG scale】 7
- 【Size】 512×768
作者おすすめの設定により、手軽に十分美しい画像を生成することができました。生成時間は全ての画像で20~21秒でした(GeForce GTX 1080利用)。
- 【Prompt】 (Best quality, 8k, 32k, Masterpiece, UHD:1.2), Photo of Pretty Japanese woman
- 【Negative prompt】 (Worst Quality:2.0)
- 【Seed】 1553913087, 1553913148, 1553913194, 1553913214, 1553913377, 1553913429






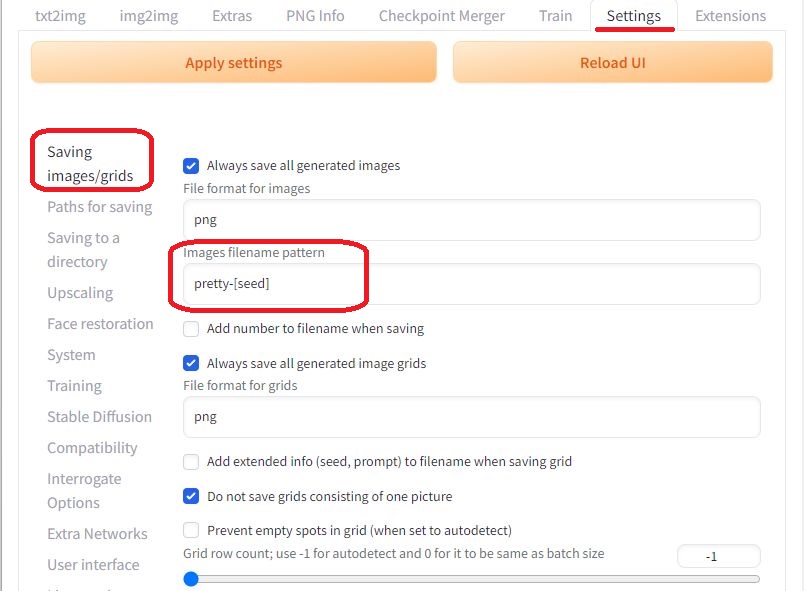
生成した画像のファイル名は、「Settings」画面の「Saving images/grids」で指定できます。図のように[seed]を含めることで、同じ画像を再現するためのSeedをファイル名に加えることができます(Seedは「txt2img」画面の「Seed」欄に指定できます)。
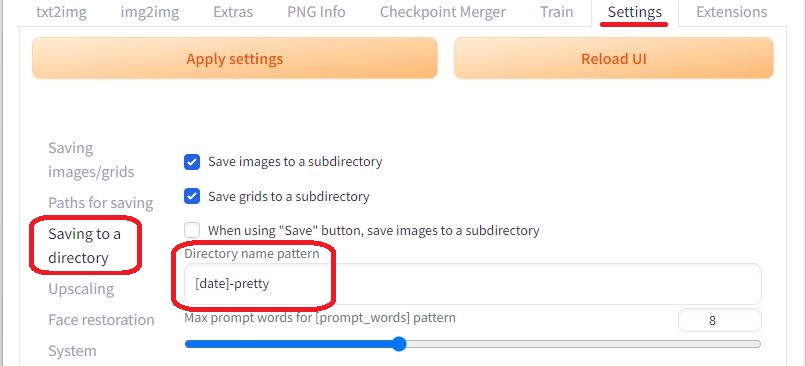
多数の画像を一度に生成する場合は、「Settings」画面の「Saving to a directory」で、保存先のフォルダー名に[date]を含めることで、日付単位で管理することができます。
最後に
古いグラフィックボードでも、時間はかかりますが十分に楽しむことができました。ただし、本格的な趣味や生業に繋げるのでしたら、もっと性能の良いグラボが必要ですね(メモリも12GB~16GBは欲しい)。今回利用したのはBRA V6ですが、BanKaiPleaseのサイトでBRA V7の開発に向けて支援金を募集しています(先行して開発版が利用できるようになります)。更なる高画質化の実現が楽しみです。